Continuant de travailler sur la nouvelle version à venir de webnaute.net (Beaucoup de travail a
été fait mais il reste encore quelques parties à faire et d’autres à terminer), j’ai été confronté
au niveau du redesign à un certain nombre de bugs de différents navigateurs. À tel point que j’ai
décidé d’en faire la liste ici pour vous en faire profiter un peu (En noir et blanc, les impressions d’écran,
je veux pas vous gâcher la surprise ^^).
Styles CSS des select
et :focus
Le bug ne se produit que sur Gecko/Linux (grrr…) lorsqu’on applique certains (n’importe quel ?) styles
CSS à un élément select lorsque celui-ci gagne l’attention (focus). Dans le cas
présent, j’appliquais un changement de couleur et de style de la bordure du select (non
fonctionnel sur Firefox 1.0 mais ok sur Deerpark). Résultat, il est nécessaire de cliquer trois fois sur
le select pour que Gecko daigne enfin dérouler la liste des options.
Pour contrer le bug, et comme je ne souhaite pas pénaliser les autres navigateurs supportant ces effets
(et notamment Deerpark sur Windows), j’ai opté pour la solution DOM, avec une petite routine qui supprime la règle CSS en cause si le
navigateur utilise Gecko (détection de fonctions spécifiques à ce moteur) et que l’OS est Linux (détection via navigator.platform, pas moyen de
faire autrement).
[Bug 149981] : must click three times on <select> form controls before dropdown appears
when pref browser.display.focus_ring_on_anything is enabled
Génération de contenu et saut de ligne
#id span::after { content: "\A"; }
Cette règle CSS fonctionne parfaitement sur Opera mais pas avec Gecko. Pour une raison qui
demeure pour moi mystérieuse, la règle CSS ne fonctionne sur Gecko que si on y ajoute la
déclaration white-space: pre; (à défaut d’utiliser pre-line qui n’est pas supporté
non plus par Gecko).
"\A" in generated content does not break lines (marqué comme étant INVALID)
La définition de la
propriété white-space dans CSS 2.1 indique en effet que les valeurs
pre, pre-wrap et pre-line doivent permettre les sauts de ligne
dans la mise en page en présence de sauts de ligne dans le code source mais aussi de sauts de ligne dans le contenu
généré par CSS.
Par opposition, cela signifierait effectivement que si white-space a la valeur
normal (valeur par défaut) ou la valeur nowrap, les sauts de ligne dans
le contenu généré (tout comme ceux présents dans le code source) doivent être normalisés (fusion des
séquences de caractères blancs en une unique espace).
Styles CSS de tableau
Imaginez le tableau (désolé, j’ai pas résisté) : Une déclaration border: 1px solid une_couleur;
sur l’élément table ainsi que sur les th, et les td parés d’un
attribut scope="row". Puis une déclaration border: 1px dashed une_couleur;
sur les éléments td. J’utilise également la pseudo-classe :empty (CSS3)
pour styler les cellules vides (celle en haut à gauche sur les impressions d’écran suivante).
Le résultat sur Firefox 1.0 (idem sur Deerpark) :
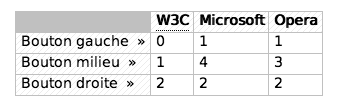
On y est presque mais mes cellules du centre n’ont pas de bordures sous forme de trait discontinu mais en trait
solide. Un autre bug lié au table est le fait que les marges externes des tableaux ne fusionnent pas dans Firefox,
pour les autres navigateurs (sauf Opera), je ne sais pas ce qu’il en est.
Le résultat sur Opera 8 :
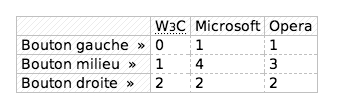
Presque parfait également, il manque juste le support de la pseudo-classe :empty.
Le résultat sur Safari 2.0 :
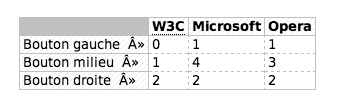
Le rendu est exactement celui attendu (le bug sur le contenu généré, "»", sera traité dans le prochain billet).
Un grand merci à J.J Solari pour les impressions d’écran.
min-width, position en absolu et Firefox
J’applique une déclaration min-width sur un élément en position absolue et
dont le contenu en-ligne est stylé d’une manière assez précise et ne doit pas revenir à la ligne. Firefox
applique bien le min-width sur le bloc, mais le contenu du bloc revient à la ligne pour ne
pas déborder de la fenêtre (alors que le min-width est justement ajouté dans l’optique de
permettre cela). Le bug peut être contourné en ajoutant également une déclaration white-space: nowrap; pour
éviter que le contenu du bloc ne revienne à la ligne.
Ce bug est corrigé dans Deerpark. Voir le bug.
Allez, ce sera suffisant pour ce soir, je vous garde le plus gros pour le prochain billet tellement
c’est rocambolesque.
Continuant mon voyage fantastique au pays des bugs, je m’en vais maintenant vous relater
comment je me suis trouvé aux prises avec deux bugs CSS teigneux, l’un affectant Safari, l’autre, beaucoup plus vicieux, continue de
me résister et affecte selon les cas au moins Opera et Firefox.
Safari et styles de sélection de texte
J’applique les styles suivants sur tous les éléments de la page et, notamment, sur des paragraphes
dont le contenu est justifié (text-align: justify;) :
*::selection { background-color: une_couleur; color: autre_couleur; }
*::-moz-selection { background-color: une_couleur; color: autre_couleur; }
Résultat sur Safari 2.0 (cliquez sur les images pour les voir grandeur réelle) :


Safari a manifestement quelques problèmes pour gérer et la justification de texte
et les styles CSS sur la sélection de celui-ci.
J’ai d’abord fait quelques recherches sur l’existence éventuelle d’un pseudo-élément
::-khtml-selection, ce qui m’aurait permis d’annuler ces styles de sélection
uniquement pour les navigateurs basés sur KHTML
(pour peu que les mots-clés CSS nécessaires fussent gérés aussi par KHTML) :
*::selection { background-color: une_couleur; color: autre_couleur; }
*::-moz-selection { background-color: une_couleur; color: autre_couleur; }
*::-khtml-selection { background-color: Highlight; color: HighlightText; }
Mais ce pseudo-élément n’existe apparamment pas. Étant donné que je me posais déjà la question de
savoir si la justification de texte était adaptée pour un rendu à l’écran, ce bug n’a fait que me
pousser à prendre la décision de retourner au plus raisonnable text-align: left;.
Feuilles de styles et encodage
Tout est parti d’un bug de Safari lié à la génération de contenu. Voici la règle CSS en cause
(vous pouvez en voir le résultat dans Firefox, Opera et Safari dans le billet précédent) :
table td[scope="row"]::after { content: "\00A0»"; }
Safari affiche donc » au lieu d’afficher » (le guillemet fermant est
précédé d’une espace insécable). J’ai d’abord simplement pensé sans réfléchir que Safari ignore
simplement le paramètre charset de l’en-tête HTTP Content-Type et utilise le jeu de caractère ISO-8859-1
pour les feuilles de styles. En fait, ça semble être un plus tordu.
Mon hypothèse est la suivante : Safari ignore effectivement le paramètre charset
de l’en-tête HTTP (premier bug) et utilise donc le jeu de caractère ISO-8859-1, mais fait
une autre boulette en résolvant les appels de caractères (ici, \00A0) avant
de convertir la feuille de style dans le même encodage (ici, l’UTF-8) que celui de la page liant
la feuille de style. Résultat, l’espace insécable se retrouve encodée deux fois de suite en UTF-8.
Le test suivant semble confirmer mon hypothèse puisque j’obtiens alors ce qu’affiche Safari (sauf l’espace,
apparamment supprimé par Safari) :
<?php
header('Content-Type: text/plain; charset=UTF-8');
echo utf8_encode("\xC2\xA0");// \xC2\xA0 est l’espace insécable encodée en UTF-8 Le résultat affiché est  suivi d’une espace
?>
Bon, mon raisonnement est débile.
Si Safari utilisait ISO-8859-1 pour la feuille de style, le guillemet fermant s’afficherait aussi de façon foireuse. Donc forcément,
Safari utilise bien l’UTF-8 pour la feuille de style
Les appels de caractères (\00A0 en tout cas) sont donc résolus et le caractère résultant encodé dans le charset
de la feuille de style. Ça semble être plus logique comme explication.
L’enfer des règles-at
Pensant d’abord pouvoir régler son compte au bug d’encodage avec la règle-at @charset
(c’était avant d’en arriver à l’hypothèse du paragraphe précédent), et malgré le bug
d’Opera et de la règle-at
@charset que j’allais devoir lui aussi tenter de contourner, je décide d’ajouter des
@charset "UTF-8"; (Rappel pour ceux qui n’ont pas vu ; Opera Mac ne semble pas affecter
par le bug de la règle @charset, seules les versions Windows et Linux le sont). Par exemple,
là :
@charset "UTF-8";
@import url("/une_feuille");
@import url("/une_autre");
html { font-size: .9em; }
Cela ne fait ni chaud ni froid à Safari (le bug du contenu généré demeure). Comme prévu, Opera perd la
boule et ignore toutes les règles-at qui suivent immédiatement (ici, les deux @import) ainsi
que la règle CSS suivante (ici, html { font-size: .9em; }).
Quant à Firefox, les tests que j’avais fait à une certaine époque m’avaient fait constater qu’il ne gérait
pas lui non plus la règle @charset, cependant, il a le bon goût de tenir compte de ce que je
lui dis dans les en-têtes HTTP, il n’était donc pas concerné par ces tests. Et pourtant,
j’ai la surprise de constater qu’il zappe lui aussi purement et simplement les deux règles
@import. Gasp…
Après pas mal d’essais infructueux, un éclair de lucidité me pousse à retourner lire la recommandation
CSS, dont la traduction n’était d’ailleurs pas accessible à ce moment-là. Heureusement, j’en
ai une copie complète sur mon disque dur ;¬). Bref, je suis tombé là-dessus :
Il ne peut y avoir qu'une règle @charset dans une feuille de style externe et elle doit survenir au
tout début de celle-ci, aucun caractère ne devant précéder. Cette règle ne doit pas apparaître dans une
feuille de style incorporée.
Ah, forcément, fallait le savoir. Je comprends mal les raisons de cette limitation. Cela veut dire
que toutes les feuilles de styles importées ont l’obligation d’être dans le même jeu de caractère que la
feuille de styles principale. Et puis il y a un autre problème du coup :
La règle @import permet aux utilisateurs l’importation de règles de style à partir d’une
autre feuille de style. Les règles @import doivent précéder toutes autres règles dans la
feuille de style.
Ah ouais… Comment que je fais moi ? Bon, heureusement, CSS 2.1 vient éclaircir
les choses comme toujours :
CSS 2.1 user agents must ignore any @import rule that occurs inside a
block or after any valid rule other than an @charset or an @import rule.
Bon, je passe sur les essais avec @namespace
pour contourner le bug d’Opera (que de toute façon, c’est pas valide puisque @charset doit être en premier)
et les heures à tester/modifier/retester sinon, ce billet risque d’être déraisonnablement long. Encore une fois,
merci à J.J Solari pour ses tests du design sur les navigateurs Mac et les impressions d’écran fournies. Il va finir par
devenir mon testeur mac attitré si ça continue ;¬)
Tiens, un bug de plus :
label { float: left; width: 15em; }/* La présence du width n’est pas significative */
label { float: none; }
La mise en flottant passe automatiquement la boîte en type bloc (comme si on mettait explicitement display: block;
(jusque là, tout est normal). Avec la règle suivante, on enlève le caractère flottant de la boîte. La boîte reste de type bloc sur
Firefox 1.0 (Deerpark n’est pas affecté par ce bug).