SQL et structure arborescente
Dans le cadre d’un projet que je développe en ce moment, j’ai besoin de stocker un arbre dans une base de données, c’est à dire un groupe d’éléments reliés par une relation de type parent-enfant. Plusieurs solutions existent :
Les listes adjacentes
C’est la méthode la plus naturelle et celle à laquelle j’ai d’abord penser. Le principe est tout simplement d’associer à chaque nœud l’identifiant du nœud parent. On peut ensuite extraire nos données de différentes façons avec des auto-jointures (voir le lien vers mysql en fin de billet).
Le problème est que cela n’est pas applicable si la profondeur de l’arbre n’est pas fixée. Il faut alors en passer par une routine récursive (en PHP dans mon cas) pour construire l’arbre et travailler dessus. C’est bourrin, c’est coûteux…
Les ensembles imbriquées ou représentation intervallaire
Moins facile à appréhender, cette technique offre en revanche une bien plus grande facilité pour lire tout ou partie de l’arbre. La plupart des opérations de lecture ne nécessitent qu’une requête SQL !
Le principe est d’assigner à chaque élément deux bornes, les descendants de cet élément étant englobés dans l’interval créé par ces deux bornes. Je me permets de copier ici la représentation visuelle en tranche donnée dans l’article de SQLpro, ça permet de tout de suite se faire une bonne idée du mécanisme :
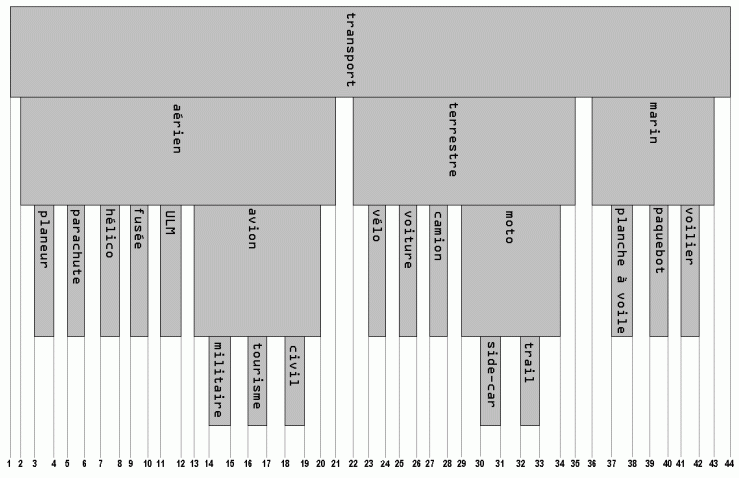
Je ne m’attarde pas sur les requêtes SQL à utiliser pour consulter un tel arbre, consultez
l’excellent article Gestion d'arbres par
représentation intervallaire
pour en savoir plus.
Ici, donc, pas besoin de récursivité, la lecture est simple et claire. Mais les choses se gâtent dès qu’on souhaite effectuer des changements sur notre arbre. Souhaite t-on ajouter un élément dans notre arbre ? Paf, trois requêtes ! Une pour décaler les bornes droite, une autre pour décaler les bornes gauches, et enfin, la requête pour insérer le nouvel élément. Et si plusieurs modifications peuvent potentiellement survenir quasiment au même moment, ne pas utiliser les transactions, et donc, dans le cas de MySQL, les tables innoDB, serait plutôt hasardeux.
Autres idées
Comme autre technique, il y en a une qui consiste à stocker carrément le chemin canonisé d’un élément à la racine. Pas super élégant et viable seulement pour des petits arbrisseaux ;¬)
J’ai vaguement pensé à stocker la structure de l’arbre sous forme XML, elle-même stockée dans la base de données, mais là comme ça, sans creuser l’idée, je me dis que les performances ne seront pas vraiment au rendez-vous. Qu’en penses-tu toi, visiteur perdu sur mon journal ? Et si tu as d’autres idées pour gérer un arbre, n’hésite pas ;¬)